


人工智能到底有多火
我相信大家之所以能来看这篇文章,也间接说明了人工智能这几年的火爆。自从基于深度学习技术的算法2012年在ImageNet比赛中获得冠军以来,深度学习先是席卷了整个学术界,后又在工业界传播开来,一瞬间各大企业如果没有AI部门都不好意思对外宣传了。BAT中,百度宣布“All In AI”,阿里建立了达摩院及AI实验室,腾讯也在前不久会议上宣布“Ai In All”,并具有腾讯优图、AI Lab和微信AI实验室。2017年7月20日,国务院发布《新一代人工智能发展规划》,将人工智能上升为国家战略,为中国人工智能产业做出战略部署,对重点任务做出明确解析,抢抓重大机遇,构筑我国人工智能发展的先发优势。
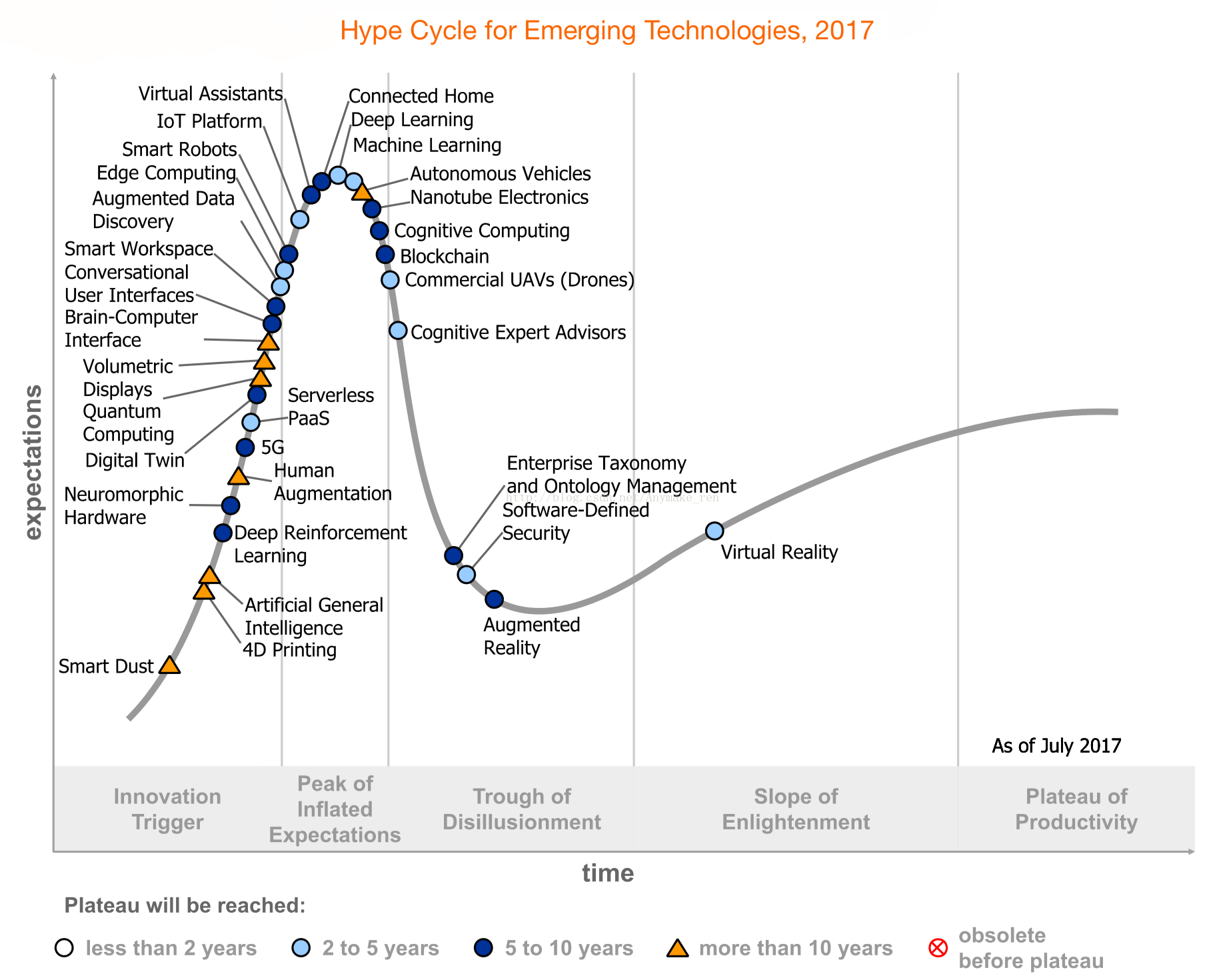
Gartner把深度学习、强化学习、常规人工智能、无人车、认知计算、无人机、会话式用户接口、机器学习、智能微尘、智能机器人、智能工作环境等均列为AI技术范畴。在人机大战等吸引眼球的活动助推下,很多AI技术目前正处在炒作的高峰期。比如深度学习、机器学习、认知计算以及无人车等。对比2016年的炒作周期曲线可以发现,有些太过超前的概念仍然不愠不火,比如智能微尘。有些概念因为炒作过高已经迅速进入到了幻灭期,比如商用无人机去年还处在触发期,今年就已经接近幻灭期边缘了。相对而言,正处在炒作高峰的深度学习和机器学习技术有望在2到5年内达到技术成熟和模式成熟。
什么是机器学习(Machine Learning,ML)?
深度学习的基础是机器学习,事实上深度学习只是机器学习的一个分支。因此我们要入门深度学习就要先了解一些机器学习的基础知识。机器学习最基本的做法,是使用算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测。与传统的为解决特定任务、硬编码的软件程序不同,机器学习是用大量的数据来“训练”,通过各种算法从数据中学习如何完成任务。
有人曾举过一个例子,很形象生动,当你使用手机的语音识别进行唤醒时,有没有想过实现这一功能的全部内部流程呢?我们日常交互的大部分计算机程序,都可以使用最基本的命令来实现,但是基于机器学习的程序却没有那么简单,想象下如何写一个程序来回应唤醒词,例如“Okay,Google”,“Siri”,和“Alexa”。如果在一个只有你自己和代码编辑器的房间里,仅使用最基本的指令编写这个程序,你该怎么做?不妨思考一下……这个问题非常困难。你可能会想像下面的程序:
run_voice_assistant()

如果你被这个问题难住了,不用担心。这就是我们为什么需要机器学习。
虽然我们不知道怎么告诉机器去把语音信号转成对应的字符串,但我们自己可以。换句话说,就算你不清楚怎么编写程序,好让机器识别出唤醒词“Alexa”,你自己完全能够 识别出“Alexa”这个词。由此,我们可以收集一个巨大的数据集(dataset),里面包含了大量语音信号,以及每个语音型号是否 对应我们需要的唤醒词。使用机器学习的解决方式,我们并非直接设计一个系统去准确地 辨别唤醒词,而是写一个灵活的程序,并带有大量的参数(parameters)。通过调整这些参数,我们能够改变程序的行为。我们将这样的程序称为模型。总体上看,我们的模型仅仅是一个机器,通过某种方式,将输入转换为输出。在上面的例子中,这个模型的输入是一段语音信号,它的输出则是一个回答{yes, no},告诉我们这段语音信号是否包含了唤醒词。
换言之,我们需要用数据训练机器学习模型,其过程通常如下:
1.初始化一个几乎什么也不能做的模型;
2.抓一些有标注的数据集(例如音频段落及其是否为唤醒词的标注);
3.修改模型使得它在抓取的数据集上能够更准确执行任务;
4.重复以上步骤2和3,直到模型看起来不错。
什么是机器学习算法?从本质上讲,机器学习采用了可以从数据中学习和预测数据的算法。这些算法通常来自于统计学,从简单的回归算法到决策树等等。
什么是机器学习模型?一般来说,它是指在训练机器学习算法后创建的模型构件。一旦有了一个经过训练的机器学习模型,你就可以用它来根据新的输入进行预测。机器学习的目的是正确训练机器学习算法来创建这样的模型。
机器学习四要素
数据(Data)
模型(Models)
损失函数(Loss Functions)
我们需要对比模型的输出和真实值之间的误差。损失函数可以衡量输出结果对比真实数据的好坏。例如,我们训练了一个基于图片预测病人心率的模型。如果模型预测某个病人的心率是100bpm,而实际上仅有60bpm,这时候,我们就需要某个方法来提点一下这个的模型了。
- 训练误差(training error):这是模型在用于训练的数据集上的误差。类似于考试前我们在模拟试卷上拿到的分数。有一定的指向性,但不一定保证真实考试分数。
- 测试误差(test error):这是模型在没见过的新数据上的误差,可能会跟训练误差很不一样(统计上称之为过拟合)。类似于考前模考次次拿高分,但实际考起来却失误了。
优化算法(Optimization Algorithms)
什么是深度学习
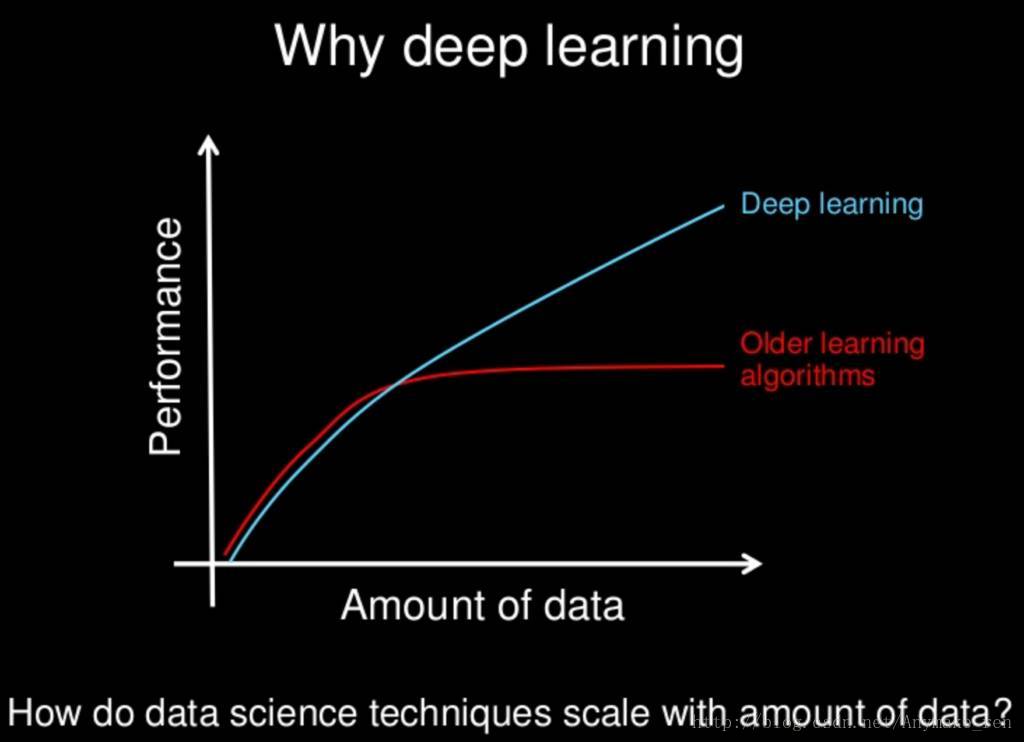

在机器学习中特征选择部分一般需要人的先验知识的介入来设计好的特征提取方法,比如人知道轮子一般是圆的,一般出现在交通工具上,有轮胎、轮毂等部件,基于先验知识,人可以选取适合提取轮子特征的方法,再设计分类器以识别轮子。而深度学习通常由多个层组成。它们通常将更简单的模型组合在一起,通过将数据从一层传递到另一层来构建更复杂的模型。通过大量数据的训练自动得到一个能识别轮子的模型,不需要人工设计特征提取环节。这是深度学习随着数据量的增加而优于其他学习算法的主要原因之一。
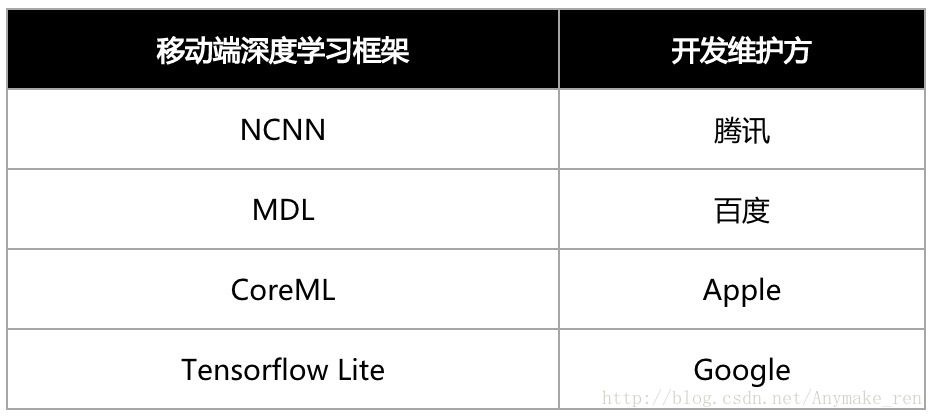
随着深度学习的发展,为了方便算法人员训练模型,调整参数等,很多公司开源了优秀的深度学习框架,到目前为止,主要的深度学习框架如下图所示。目前工业界用的比较多的是Caffe和TensorFlow,Caffe主要在计算机视觉上用的较多,TensorFlow由谷歌开源,相关文档较好,适用范围广,基于Python语音,入门简单,建议新手入门可以选择TensorFlow。但是这些只是深度学习的平台框架而已,真正重要的还是学习好深度学习的理论,有了理论各种平台都不是问题。

TensorFlow简介
TensorFlow是专门为机器学习而设计的快速数值计算Python库,它由谷歌开源,旨在让世界各地更多的研究人员和开发人员掌握深度学习。为了加速深度学习领域的发展,2015年11月9日,Google发布深度学习框架TensorFlow并宣布开源。在短短的一年时间内,在GitHub上,TensorFlow就成为了最流行的深度学习项目。
TensorFlow在计算机视觉、语音识别、推荐系统和自然语言处理等场景下都有丰富的应用。虽然Tenforflow开源时间刚满一年,但是它正在以迅猛的速度渗入到我们的寻常生活中。它支持Linux平台,Windows平台,Mac平台,甚至还宣称要发布相应的移动端平台。其次,TensorFlow提供了非常丰富的深度学习相关的API,可以说目前所有深度学习框架里,提供的API最全的,包括基本的向量矩阵计算、各种优化算法、各种卷积神经网络和循环神经网络基本单元的实现、以及可视化的辅助工具、等等。
学习资料
书籍:
第一本是《白话深度学习与TensorFlow》,这本书写的非常通俗易懂,没有太多理论知识介绍,基本是深度学习的基础知识和TensorFlow的相关例程,适合没有深度学习基础,想入门深度学习的人看。
网络资源:
5.想学习caffe框架的,也可以参考徐其华的博客:http://www.cnblogs.com/denny402/tag/caffe/
结语
 您阅读这篇文章共花了:
您阅读这篇文章共花了:




 相关文章
相关文章本文地址:https://blog.hellozwh.com/?post=340
版权声明:若无注明,本文皆为“起点终站”原创,转载请保留文章出处。






-
 making 说:感谢分享
making 说:感谢分享 -
 ak 说:感谢分享
ak 说:感谢分享 -
 J 说:✅ 看 魸【36me.xyz】偸 啪【36me.xyz】佬 呞 机~你 慬 的 ✅
J 说:✅ 看 魸【36me.xyz】偸 啪【36me.xyz】佬 呞 机~你 慬 的 ✅ -
 九江市 说:借鉴借鉴
九江市 说:借鉴借鉴 -
九江市 说:借鉴借鉴

